NVIDIA发布Nemotron 3.5 ASR 实现单模型覆盖40种语言实时转写
背景与意义
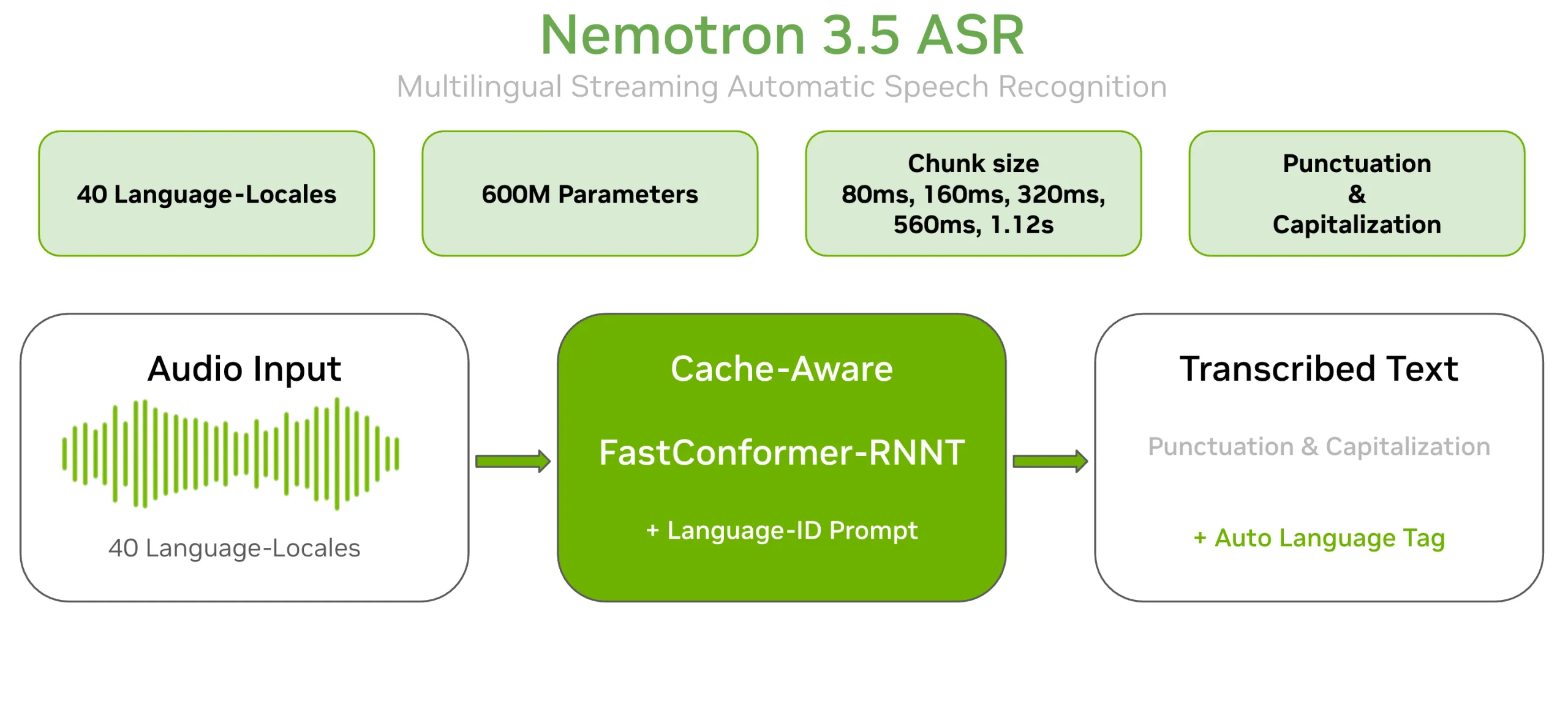
NVIDIA的Nemotron Speech团队在2026年6月正式发布了Nemotron 3.5 ASR,这是一款面向实时语音转写的多语言自动语音识别模型。相较于传统的批量模型,Nemotron 3.5 ASR在保持高准确率的同时,将端到端延迟压缩至80 ms,实现了真正的流式交互,满足智能客服、实时字幕等业务对低时延的苛刻要求。
模型架构
- Cache‑Aware FastConformer‑RNNT:模型核心由24层FastConformer编码器和RNNT解码器组成。FastConformer在注意力计算上实现线性可扩展性,配合缓存机制避免重复计算。
- 缓存感知设计:在流式推理时,模型会缓存前一帧的自注意力与卷积激活,将其复用到后续帧,保证每帧音频仅处理一次,显著降低计算成本与功耗。
多语言覆盖与实时性能
Nemotron 3.5 ASR通过提示式语言ID条件化,单一600 M参数检查点即可覆盖包括英语、法语、德语、西班牙语、阿拉伯语、日语、韩语、普通话、印地语、泰语等在内的40种语言/地区。用户可显式指定target_lang获取最佳精度,或使用target_lang=auto让模型自行检测语言并在句末输出语言标签,实现混语音流的无缝转写。
延迟调节机制
模型提供att_context_size参数作为延迟‑精度旋钮。
- [56,0] → 80 ms 超低时延,适用于语音助理等交互场景。
- [56,13] → 1.12 s 高精度模式,适合需要最高识别准确率的批处理任务。 同一检查点即可覆盖全范围,无需重新训练,极大提升部署灵活性。
微调效果与实测数据
NVIDIA在公开的FLEURS基准上对希腊语和保加利亚语进行了短时微调,使用相同的Cache‑Aware FastConformer‑RNNT流程。
- 希腊语:WER从35%降至24%,相对提升32%。
- 保加利亚语:WER从22%降至15%,相对提升31%。 这些结果均在80 ms最低时延设置下测得,证明即便在极端低延迟下,模型仍具备可观的可调精度空间。
开源与可用性
模型权重采用OpenMDW‑1.1许可证,已同步至Hugging Face,支持自行部署。运行时依赖NVIDIA NeMo 2.6.6及以上版本,兼容Ampere、Hopper、Blackwell、Lovelace、Turing、Volta以及Jetson系列GPU。NVIDIA计划在本月内推出基于gRPC的NIM服务,进一步降低企业接入门槛。
行业对比与前景
与OpenAI Whisper large‑v3(离线批处理)以及Deepgram Nova‑3(流式但仅支持10+单语种)相比,Nemotron 3.5 ASR在模型体积、语言覆盖与原生流式能力上形成明显差异化;其17倍并发流的报告数据(基于H100)表明在大规模部署场景下可显著降低算力开支。随着多语言实时交互需求的增长,Nemotron 3.5 ASR有望成为企业级语音 AI 平台的首选底层模型。
关键要点
- 600 M 参数、单检查点覆盖40种语言;
- Cache‑Aware FastConformer‑RNNT 实现每帧一次计算;
- 延迟可调 80 ms‑1.12 s,无需再训练;
- 开源权重、可自行部署,配套即将上线的NIM服务。
“Nemotron 3.5 ASR的出现,为实时多语言语音交互设定了新的基准。”——NVIDIA官方发布会