Meta推出Autodata让模型自生成训练数据 开启合成数据新范式
•4 阅读•3分钟•前沿
生成式AIMetaAutodata
Jesus Rodriguez••4 阅读•3分钟•前沿
研究背景
过去几年,AI性能的提升主要依赖模型规模、算力和更好的架构。虽然数据质量同样重要,但往往被视作训练前的准备工作:爬取、清洗、标注,然后交给模型训练。Meta在最新的《Autodata》论文(arXiv:2606.25996,2026年6月发布)中,提出将数据生产本身视作一个可学习的过程,试图让模型在训练循环中主动生成并改进自己的训练样本。
Autodata核心思路
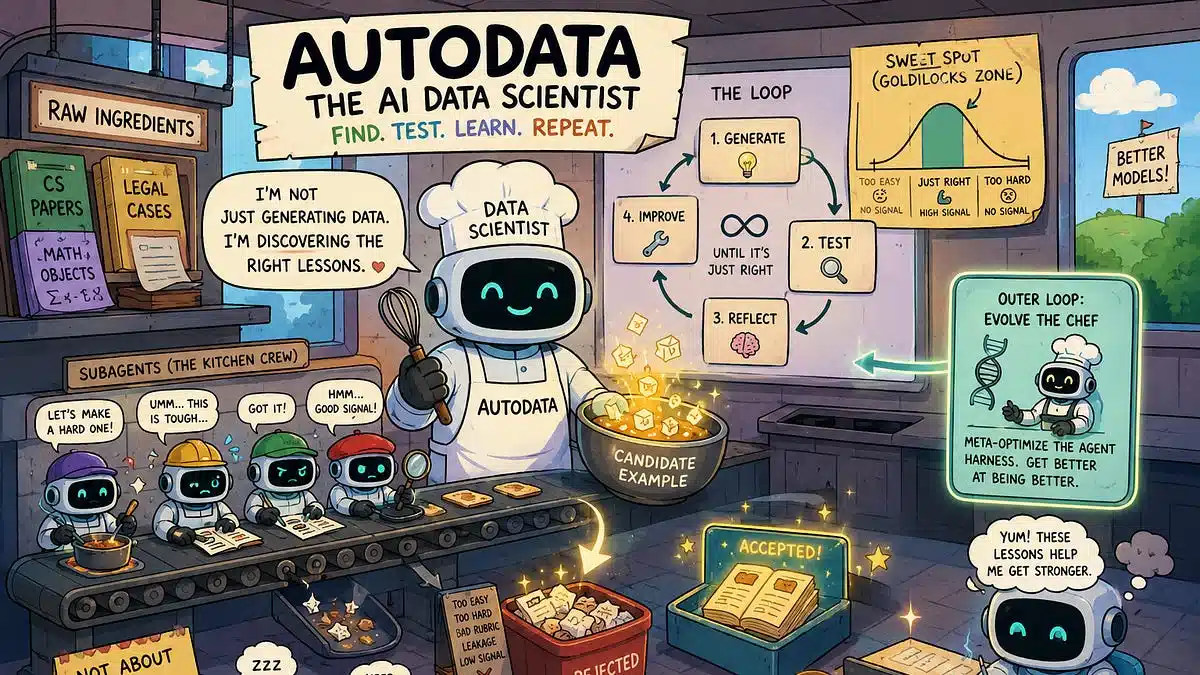
- 数据生成即研究循环:系统内部的AI代理先生成一批合成样本,随后对这些样本进行评估,捕获模型在这些样本上的错误或不足。
- 自我反馈与配方更新:基于评估结果,代理会调整生成配方(例如提示词、噪声水平、分布参数),再生成新一轮样本。
- 迭代收敛:循环多次后,生成的数据分布逐步逼近模型的学习需求,实现“数据自适应”。
这一过程不同于传统的“一次性合成”或“强模型大规模生成”,而是把数据生成纳入训练的闭环,使得数据本身具备了类似强化学习的探索与改进能力。
实验与初步结果
论文在多个公开基准上进行了验证:
- 在文本分类任务中,使用Autodata生成的微调样本使模型在少样本环境下提升约3% F1。
- 在视觉问答(VQA)任务中,基于Autodata的合成对话提升了约2.5% 的准确率。
- 与传统合成数据流水线相比,Autodata在相同算力预算下产生的有效样本数量约高出20%。
值得注意的是,作者并未声称该方法能够完全取代真实数据,而是强调其在数据稀缺或标签成本高昂的场景下的增益潜力。
行业意义与潜在影响
- 降低标注成本:通过让模型自行发现训练盲点,可在无需大量人工标注的前提下补齐数据缺口。
- 提升模型鲁棒性:持续的错误检测与数据迭代帮助模型捕获长尾分布,减少对特定数据偏差的依赖。
- 推动合成数据标准化:Autodata提供了一套可复现的生成‑评估‑迭代框架,为业界制定合成数据评估基准奠定基础。
未来展望
Meta团队计划将Autodata扩展至多模态场景,探索图像、音频和文本的跨模态合成循环。此外,如何在大规模分布式训练中高效实现该闭环、以及防止生成数据的模式崩塌(mode collapse)仍是后续研究重点。业界已有初步尝试将类似思路用于大语言模型的自监督微调,预计在下一代基础模型训练中,Autodata或其衍生技术将成为重要组成部分。
“数据不再是静态资源,而是可以被模型主动探索和改进的动态资产。” — Meta Autodata论文作者团队
小结
Meta的Autodata将合成数据从被动工具转化为主动学习环节,为解决数据瓶颈提供了新思路。随着该技术在更多任务和规模上的落地,合成数据有望在提升模型性能、降低成本方面发挥更大作用。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。