NVIDIA NeMo AutoModel提升MoE模型微调效率,训练吞吐提升超3倍
•1 阅读•6分钟•前沿
NVIDIAMoENeMo AutoModelExpert ParallelismTransformerEngine
•1 阅读•6分钟•前沿
背景
随着 Mixture‑of‑Experts(MoE)模型成为前沿大模型的主流架构,训练过程面临路由、专家矩阵乘、权重切片等瓶颈。传统的 HuggingFace Transformers 在 v5 版本已提供专家后端、动态权重加载和张量并行,但在多节点大模型(如 550B Nemotron‑3 Ultra)仍会因显存不足或通信开销过大而失效。NVIDIA 为此推出 NeMo AutoModel,在保持 from_pretrained() 单行 API 不变的前提下,引入三大核心加速:
- Expert Parallelism (EP):在 GPU 之间水平切分专家权重,显著降低单卡显存占用。
- DeepEP:将专家路由的 AllGather/ReduceScatter 与计算融合为一体的自定义 kernel,实现通信‑计算重叠。
- TransformerEngine (TE) 核心:使用 TE 的 fused attention、线性层和 RMSNorm,提升整体算子效率。
关键特性
- API 兼容:NeMoAutoModelForCausalLM 直接继承 HuggingFace 的
AutoModelForCausalLM,仅需将import换成from nemo_automodel import NeMoAutoModelForCausalLM即可。 - 模型覆盖:对 Qwen3、Nemotron、GPT‑OSS、DeepSeek V3 等主流 MoE 架构提供 hand‑tuned 实现,未覆盖模型仍可使用 HF 原生优化。
- 灵活分布式:支持
fsdp2、ep_size等配置,用户只需在distributed_setup中声明 EP 大小,即可在 8‑GPU 单机或 16‑节点大规模环境下启动训练。
性能评测
| 模型 | 环境 | TPS/GPU(NeMo) | TPS/GPU(Transformers v5) | 加速比 | 峰值显存(GiB) | 显存节省 |
|---|---|---|---|---|---|---|
| Nemotron‑3 Ultra 550B | 16×H100 80GB | 815 | — (v5 内存溢出) | — | 58.2 | — |
| Qwen3‑30B‑A3B | 8×H100 80GB | 11,340 | 3,075 | 3.69× | 48.1 vs 68.2 | ‑29% |
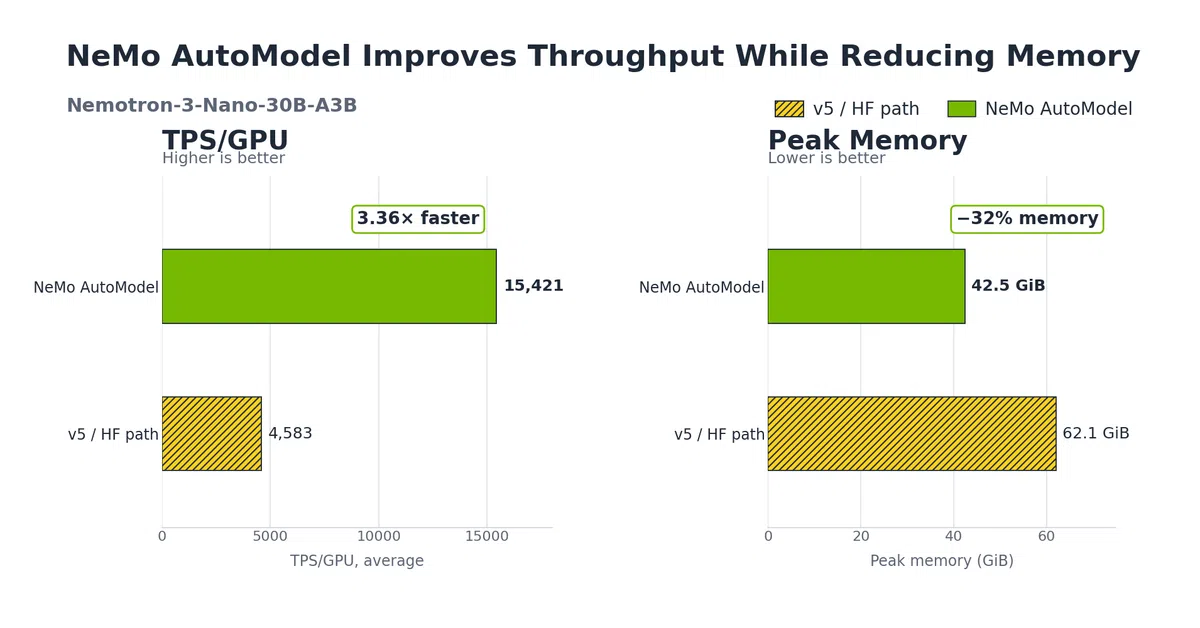
| Nemotron‑3 Nano 30B‑A3B | 8×H100 80GB | 15,421 | 4,583 | 3.36× | 42.5 vs 62.1 | ‑32% |
其中,
TPS/GPU表示每块 GPU 每秒处理的 token 数,数值越高说明训练吞吐越快。NeMo AutoModel 在相同硬件配置下,前向+反向总时延分别下降约 2.6‑4.3 倍。
加速来源拆解
- Expert Parallelism:将专家权重按 EP=8 均匀切分,使每块卡只保留 1/8 的专家参数,显存直接下降约 30%。
- DeepEP:通过自定义 All‑to‑All kernel 将路由通信与专家计算合并,减少了通信等待时间。
- TransformerEngine:TE 的 fused attention 与线性层在所有层级提供 10‑20% 的基准加速,叠加在 EP 与 DeepEP 之上形成整体 3‑4 倍提升。
实际使用指南
import os, torch, torch.distributed as dist
from nemo_automodel import NeMoAutoModelForCausalLM
from nemo_automodel.recipes._dist_utils import create_distributed_setup_from_config
os.environ["LOCAL_RANK"] = "0"
dist.init_process_group(backend="nccl")
dist_setup = create_distributed_setup_from_config({
"strategy": "fsdp2",
"ep_size": 8,
})
model = NeMoAutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
dtype=torch.bfloat16,
distributed_setup=dist_setup,
)
dist.destroy_process_group()
以上代码展示了在 8 GPU 环境下启动 EP=8 的完整流程,几乎不需要额外的代码改动。
行业意义
- 降低门槛:研究者和企业无需重写训练脚本,只换一行 import 即可获得数倍加速。
- 推动大模型落地:显存节省让 550B 级别模型在多节点上可行,为生成式 AI、检索增强等业务提供更经济的训练方案。
- 生态兼容:NeMo AutoModel 保存的 checkpoint 仍为标准 HF safetensors,可直接在 vLLM、SGLang 等推理框架中部署,保证研发‑推理闭环。
综上所述,NVIDIA NeMo AutoModel 为 MoE 系列模型的微调提供了“一键升级”路径,在训练效率、显存占用和生态兼容性上实现了全方位突破,预示着大规模生成式 AI 进入更高效的商业化阶段。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。