Adam自适应学习率破解SGD频率偏差 助力稀有词学习
•22 阅读•3分钟•前沿
生成式AITransformerAdamSGD
•22 阅读•3分钟•前沿
背景与问题
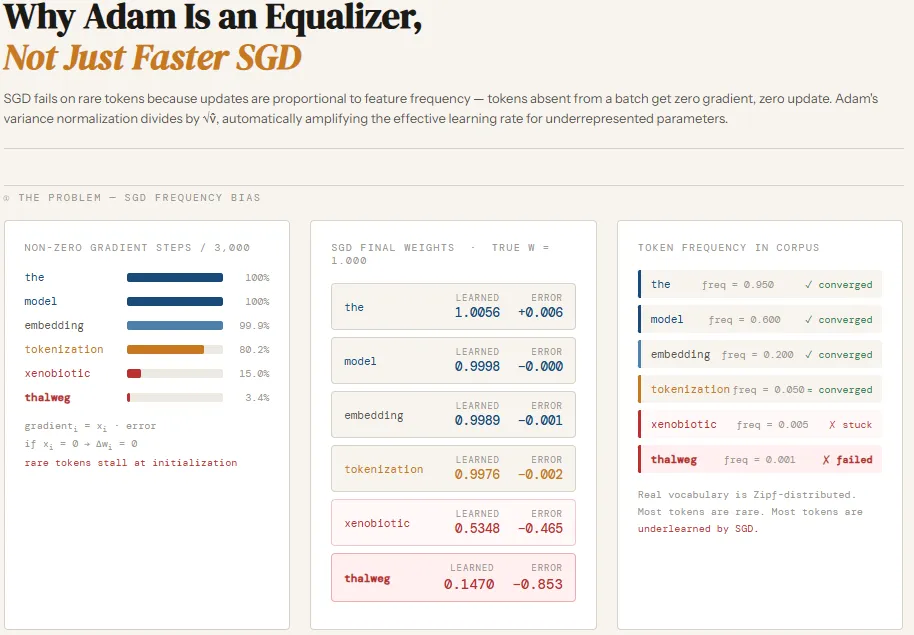
现代大语言模型的训练语料中,词频呈长尾分布——少数高频词几乎出现在每一句,数十万甚至上百万的低频词却只有零星出现。传统的**随机梯度下降(SGD)**使用统一学习率,导致高频词的参数快速收敛,而稀有词的参数在数千甚至上万步内几乎没有收到有效梯度,学习停滞。
实验设计
为 isolate 频率因素,作者构造了一个仅包含六个词的合成词表,词频跨越四个数量级:the(0.95), model(0.60), embedding(0.20), tokenization(0.05), xenobiotic(0.005), thalweg(0.001)。所有词的真实权重均设为 1.0,训练目标为线性模型的输出加噪声。实验在相同的学习率(0.05)、批大小(32)和训练步数(3000)下,分别使用 SGD 与 Adam 两种优化器进行训练,并记录每个参数的权重轨迹、非零梯度次数以及 Adam 的方差估计。
SGD 的表现
- 高频词(如
the、model)在数百步内权重即可逼近 1.0,梯度几乎每步都有。 - 稀有词(
xenobiotic、thalweg)的梯度出现率仅为 15% 与 3.4%,对应的权重分别停留在约 0.53 和 0.15,远离目标值。 - 结果显示,统一学习率无法克服梯度稀疏导致的学习偏差。
Adam 的优势
Adam 为每个参数维护 一阶动量 m 与 二阶方差 v,并在更新时除以 (\sqrt{v})。稀有词因梯度出现稀少,累计的方差 v 极小,导致 有效学习率 被放大数十倍(最稀有的 thalweg 达到约 41×)。
- 所有六个词的最终权重均接近 1.0,稀有词的误差与高频词持平。
- Adam 自动实现了 频率平衡,无需人为调节学习率或采样策略。
关键发现
- 频率偏差是训练稀疏特征的根本瓶颈,SGD 在长尾分布下表现不佳。
- 方差归一化是 Adam 区别于 SGD 的核心优势,能够依据梯度历史自动调节每个参数的步幅。
- 实验结果在对数坐标上呈现出 频率 vs 有效学习率的逆比例关系,验证了理论预期。
影响与展望
该研究对大规模语言模型的微调与稀疏特征学习具有直接指导意义。未来工作可进一步探索:
- 将 Adam 的自适应机制与 稀疏正则化 结合,提升模型在低资源语言上的表现。
- 在 Transformer 等更复杂结构中验证方差归一化对稀有 token 注意力权重的影响。
- 开发针对特定频率分布的学习率调度器,以在保持收敛速度的同时进一步缩小稀有词误差。
“Adam 并未被告知哪些词是稀有的,它仅凭梯度的方差自行完成了均衡。”——实验作者
整体来看,Adam 的自适应学习率为解决 LLM 训练中的频率偏差提供了简洁而高效的方案,值得在实际生产流水线中推广使用。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。