EAGLE 3.1发布:解决推理中注意力漂移显著提升推测解码稳定性
•146 阅读•4分钟•前沿
vLLMKimiSpeculative DecodingTorchSpec
•146 阅读•4分钟•前沿
背景
在大模型推理加速中,推测解码(speculative decoding) 通过让小型草稿模型提前生成多个候选 token,随后由目标模型一次性验证,从而提升吞吐。EAGLE 系列已成为业界广泛部署的方案,EAGLE 3 在多场景表现优秀,但在实际生产环境下出现了注意力漂移导致的稳定性下降。
问题根源
EAGLE 3 在以下三类输入下表现不佳:
- 不同的聊天模板;
- 超长上下文;
- 超出分布的系统提示。 根本原因是草稿模型在递归推测深度增加时,注意力逐渐从原始上下文(sink token)转向自身已生成的 token,出现 attention drift。两大技术细节进一步放大了该效应:
- 融合输入的隐藏层表示失衡,高层隐藏状态主导草稿模型输入;
- 未归一化的残差路径导致隐藏状态幅度随推测步数累积增长。
关键架构修复
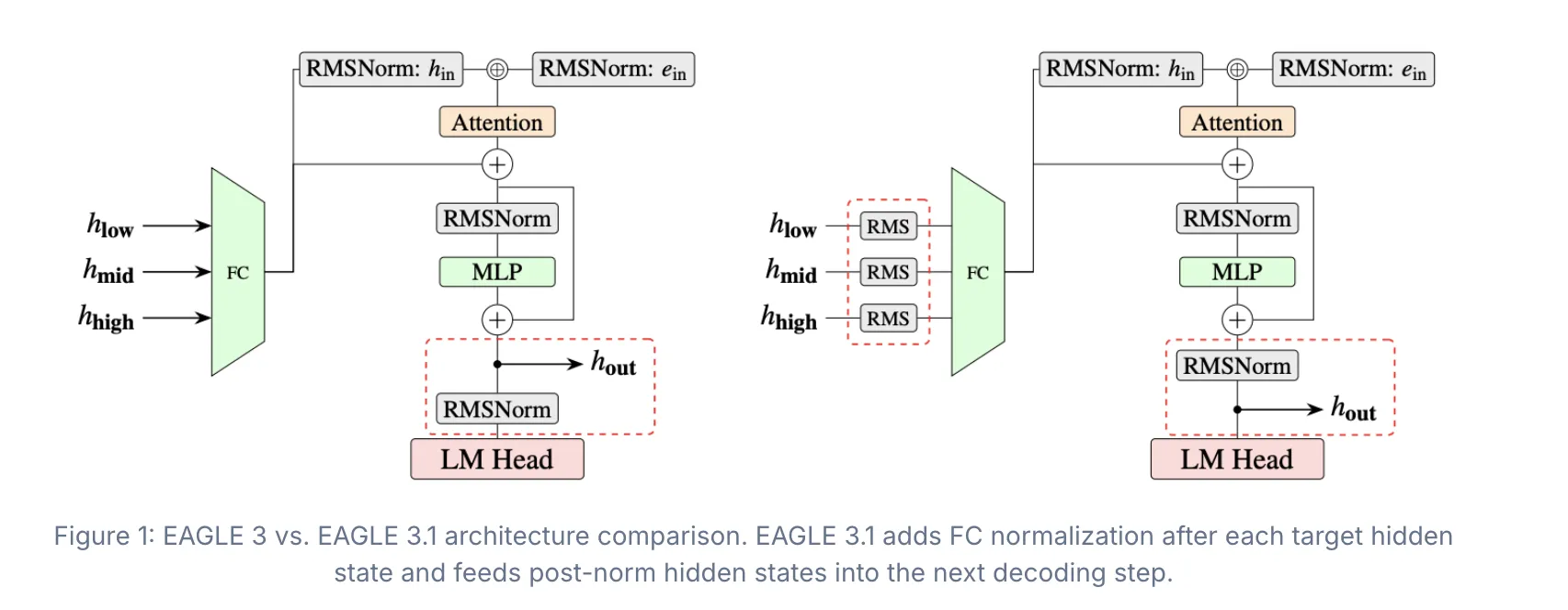
EAGLE 3.1 引入了两项核心改进:
- FC 归一化:在每个目标模型隐藏层输出后、全连接层前执行归一化,限制隐藏状态幅度,防止随步数膨胀。
- 后归一化(post‑norm)反馈:将归一化后的隐藏状态直接喂入下一个推测步骤,使草稿模型更像递归调用,而非简单堆叠层。
这两项措施共同抑制了注意力漂移,使草稿模型在深层推测时保持对原始上下文的聚焦。
性能提升
在 Kimi‑K2.6(NVFP4)上使用 vLLM 0.22 进行 SPEED‑Bench 编码基准测试,EAGLE 3.1 相比基线实现了:
- 2.03× 单用户吞吐(并发 1)
- 1.71× 并发 4 时保持提升
- 1.66× 并发 16 时仍高于基准
- 长上下文工作负载下接受长度提升至 2 倍
这些数字表明,在保持输出质量不变的前提下,EAGLE 3.1 能显著加速推理,特别适用于对响应时延敏感的聊天和代码生成服务。
部署与开源
- vLLM 集成:EAGLE 3.1 以配置驱动方式加入现有 EAGLE 3 实现,兼容旧 checkpoint,用户仅需在
speculative-config中指定method":"eagle3"即可使用。 - TorchSpec 支持:TorchSpec 提供了高效的训练管线,降低了实验成本,帮助研究者快速迭代下一代推测解码算法。
- 开源草稿模型:基于 TorchSpec 与 vLLM,团队在 HuggingFace 上公开了 Kimi‑K2.6‑EAGLE3.1 草稿模型,供社区直接部署和二次研发。
行业影响
EAGLE 3.1 的发布标志着推测解码从“实验性加速”迈向“生产级可靠性”。随着大模型服务规模化,推理成本已成为瓶颈,可靠的加速技术将直接决定云服务商和企业级 AI 产品的竞争力。未来,更多模型(包括国产大模型)有望借助该框架实现低延迟高吞吐的部署。
业内观点:
“EAGLE 3.1 的两项归一化改进在理论上解决了长期困扰推测解码的注意力漂移问题,为大模型推理提供了可落地的性能提升方案。” — vLLM 核心贡献者
如需使用 EAGLE 3.1,请参考 vLLM 官方文档的 speculative‑decoding 示例,或直接在 HuggingFace 下载对应草稿模型。
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。