StepFun发布StepAudio 2.5 Realtime 实时语音大模型,实现角色扮演一致性与声学感知
•104 阅读•4分钟•前沿
RLHFStepFunStepAudio 2.5 Realtime声学感知
•104 阅读•4分钟•前沿
关键发布
上海AI实验室StepFun于2026年5月正式发布 StepAudio 2.5 Realtime,这是一款面向实时交互的端到端语音大型语言模型(LLM)。不同于传统的语音识别‑理解‑合成流水线,模型实现了音频输入即音频输出的单体化处理,能够在毫秒级延迟下完成语言理解、推理与语音合成。
三大技术支柱
- 百万级角色数据增强 从1万余条高质量角色描述出发,StepFun利用算法自动扩展至百万级特征矩阵,并结合海量真实对话样本进行训练,确保模型在长尾角色场景下仍能保持稳定表现。
- 角色扮演专属RLHF对齐 为解决对话期间的“脱离角色”(OOC)问题,团队专门构建了角色一致性奖励模型,并通过强化学习从人类反馈(RLHF)进行微调,使模型在角色扮演情境下能够持续保持设定人格。
- 统一的语音理解‑生成框架 继承StepAudio 2.5的文本‑转‑语音能力,模型在同一网络中同时学习语音特征的理解与生成,实现了“全局情绪基调设定”与“句内细节雕刻”,能够在一次响应中调节整体情感基调并微调每句话的音色、语速等细节。
声学感知能力
StepAudio 2.5 Realtime 在声学感知基准上取得 82.18 分,能够捕捉说话者的语速、情绪、年龄甚至疲劳度等非语言信息。模型通过直接分析音频波形,而非转写文本,实现了对声音细微变化的高灵敏度判断,从而在对话中做出更符合用户情境的回应。
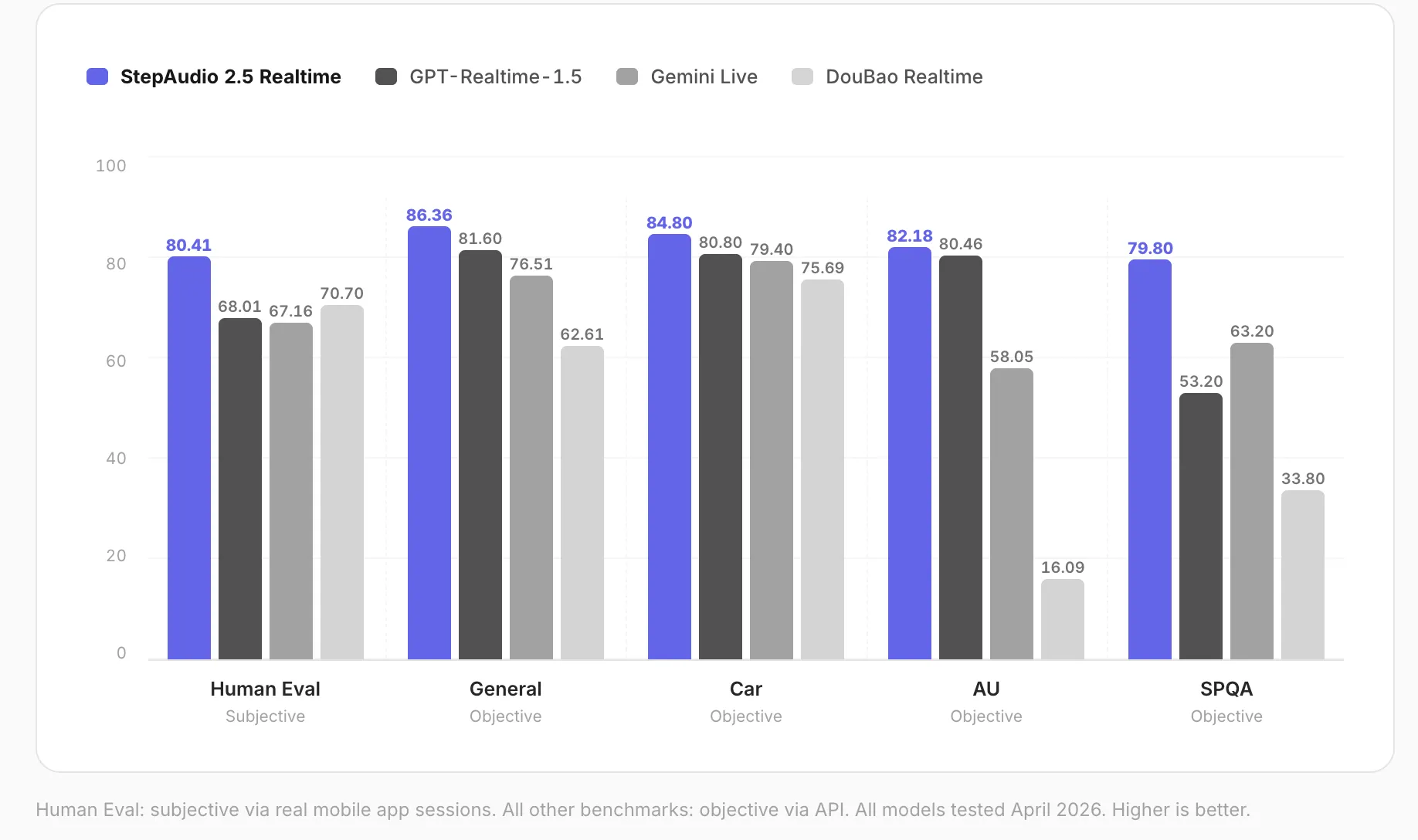
基准评测概览
| 维度 | 分数 |
|---|---|
| 人类评估(主观) | 80.41 |
| 普通对话(客观) | 86.36 |
| 汽车场景对话 | 84.80 |
| 语音问答(11项) | 79.80 |
| 声学感知 | 82.18 |
上述结果均来自2026年4月的内部评测,StepAudio 2.5 Realtime 在全部五项指标中均位居第一,显示出在实时语音交互领域的领先优势。
API 接入方式
模型通过 WebSocket 提供服务,接入地址为 wss://api.stepfun.com/v1/realtime,模型标识为 step-2.5-realtime。开发者可直接将音频流推送至该端点,实现低延迟的双向语音交互。
行业意义与展望
- 角色扮演应用:从虚拟客服到沉浸式游戏,精准的角色保持将显著提升用户沉浸感。
- 情感计算:声学感知让系统能够在通话中实时感知用户情绪,推动情感计算向更细粒度发展。
- 多语言支持:中英双语能力降低了跨语言部署门槛,为国内外企业提供统一的语音交互解决方案。
StepFun 表示,后续将继续开放模型卡片、演示页面以及社区支持,计划在2026年底前推出面向企业的 SaaS 版服务,助力各行业快速构建具备角色一致性与情感感知的语音交互产品。
“实时、端到端、并具备深度情感感知的语音模型,是我们对下一代人机交互的核心设想。” — StepFun 技术负责人
本文是对第三方新闻源的主观解读。消息可能出现过时、不准确、歧义或错误的地方,仅供参考使用。点击此处查看消息源。